
Myths about duplicate content often cloud the understanding of best practices. This comprehensive exploration delves into the common misconceptions surrounding duplicate content, dissecting the reasons behind the misunderstandings and their impact on website strategies. We’ll unravel the truth behind these myths, showing you how to avoid common pitfalls and implement effective strategies for maintaining unique and engaging content.
From technical causes to content strategy, this in-depth guide examines various facets of duplicate content, including its impact on search engine rankings and the consequences of neglecting these issues. We’ll also explore the challenges of handling duplicate content across different languages and regions, discussing the importance of canonicalization and redirects in maintaining a strong online presence.
Common Misconceptions
Navigating the complexities of search engine optimization () can be challenging, especially when misinformation abounds. One significant hurdle website owners face is the persistent misunderstanding surrounding duplicate content. These misconceptions can lead to detrimental strategies and hinder a website’s performance. Let’s delve into the top myths and debunk the falsehoods.
Top 5 Myths About Duplicate Content
Understanding the common misconceptions about duplicate content is crucial for implementing effective strategies. Misconceptions often arise from a lack of clarity regarding search engine algorithms and best practices. These myths can lead to costly errors and hinder organic search visibility.
Ever heard the myth that duplicate content is a death sentence for SEO? While it’s true that search engines don’t love it, it’s not quite as black and white as some people claim. Creating compelling investor pitches, like the ones you can learn to craft at create pitch deck investors , requires a nuanced approach to content creation.
Ultimately, the key to avoiding duplicate content issues lies in focusing on high-quality, original content that adds value to your audience, not just stuffing keywords for search engines.
- Myth 1: All duplicate content is penalized by search engines.
- Myth 2: Exact duplicates are the only issue.
- Myth 3: Content mirroring is a harmless tactic.
- Myth 4: Using synonyms for s is a form of duplicate content.
- Myth 5: Duplicate content only affects the ranking of the copied page.
Detailed Explanation of the Myths
These prevalent myths, while seemingly straightforward, contain hidden complexities and nuances. Understanding their origins and impact is key to avoiding costly mistakes.
| Myth | Explanation | Impact on Website Strategies | Correction |
|---|---|---|---|
| All duplicate content is penalized by search engines. | This myth stems from a fear of being penalized for any instances of duplicate content. While search engines do penalize blatant content duplication, they also recognize and reward unique, valuable content. | Website owners might avoid updating content, fearing any new version will be seen as duplicate content. This can lead to outdated information and missed opportunities for improvement. | Focus on creating high-quality, original content that provides value to users. Address duplicate content issues by ensuring each page offers unique value. |
| Exact duplicates are the only issue. | This misunderstanding overlooks the more subtle forms of duplicate content, like near-identical content, or very similar content on multiple pages. | Website owners may miss critical duplicate content on their site, failing to address potentially significant problems. | Use tools to identify instances of near-identical or highly similar content. Review and modify affected pages to create unique content. |
| Content mirroring is a harmless tactic. | The idea that mirroring content across multiple domains or subdomains will boost is false. Search engines recognize this practice as a form of duplicate content. | Website owners might try to artificially inflate their presence by mirroring content, but this can lead to lower rankings. | Focus on creating a single authoritative source of content. Use canonical tags to direct search engines to the preferred version. |
| Using synonyms for s is a form of duplicate content. | This misconception arises from the idea that using synonyms is somehow creating duplicates, whereas it actually enhances the user experience. | Website owners might restrict the use of synonyms to avoid perceived duplicate content, which limits the variety of expressions used for the same topic. | Utilize synonyms and related s to improve the diversity of your content. Ensure that each page addresses the same topic from a unique perspective. |
| Duplicate content only affects the ranking of the copied page. | This belief underestimates the impact of duplicate content on the overall site health and ranking. Search engines see it as a sign of low-quality content. | Website owners might focus only on fixing the copied page without recognizing that the entire site could be impacted. | Conduct a comprehensive site audit to identify and fix all instances of duplicate content. Prioritize quality over quantity in content creation. |
Impact on Search Engine Ranking
Duplicate content, while seemingly a minor issue, can significantly impact a website’s search engine rankings. Search engines prioritize delivering relevant and unique content to users, and duplicate content often undermines this goal. This can lead to lower rankings, reduced visibility, and ultimately, decreased organic traffic. Understanding how search engines handle duplicate content and the factors influencing its impact is crucial for website owners and professionals.Search engines employ various techniques to identify and address duplicate content.
These methods aim to ensure that only the most relevant and authoritative versions of a page are presented to users. The severity of the impact depends on several factors, including the extent of duplication, the nature of the duplicated content, and the overall authority of the websites involved. A deeper dive into the intricacies of search engine algorithms and their approaches to handling duplicate content will shed light on this complex issue.
Search Engine Approaches to Duplicate Content
Search engines utilize sophisticated algorithms to identify duplicate content. These algorithms examine various aspects of web pages, including the content itself, the HTML structure, and the source code. One common approach involves comparing the content of different pages to identify overlaps. If substantial overlap is detected, search engines prioritize the most authoritative and well-established source. This often means pages with higher domain authority, older content, and a strong backlink profile are favored.
Search engines also evaluate the context surrounding the duplicate content, considering factors like user engagement and the overall website structure.
Factors Determining the Severity of the Impact
The impact of duplicate content on search engine rankings varies considerably. Several factors influence the severity of the issue. The extent of the duplication, the nature of the duplicated content, and the overall quality of the website play a crucial role. If the duplicate content is a minor issue, such as a few repeated phrases or minor formatting differences, the impact might be negligible.
However, if significant portions of the content are duplicated across multiple pages, the impact can be more severe, potentially leading to lower rankings or even penalties. The quality of the original content also matters. If the duplicated content is of low quality or lacks originality, it will likely have a negative impact on search engine rankings.
Comparison of Different Search Engine Algorithms
Different search engine algorithms employ varying approaches to handling duplicate content. While the core principles remain similar, there are subtle differences in how each engine prioritizes certain factors. For example, some algorithms might place more emphasis on the age of the content, while others might prioritize user engagement metrics. This variability necessitates a nuanced understanding of the specific algorithm’s characteristics to effectively optimize content for search engines.
Google, Bing, and other search engines all use proprietary algorithms, and these algorithms are constantly evolving.
Scenarios of Duplicate Content, Search Engine Responses, and Potential Solutions
| Scenario | Search Engine Response | Potential Solutions | Severity |
|---|---|---|---|
| Identical content on multiple pages within the same website | Search engine might index only one version, potentially penalizing other pages. | Canonicalization tags to specify the preferred version, ensuring consistent internal linking. | Medium |
| Nearly identical content on different websites | The search engine prioritizes the most authoritative and relevant source. | Creating unique and original content, improving site authority, and building high-quality backlinks. | High |
| Content scraped from other websites | Search engines penalize the website for plagiarism. | Develop unique content, avoid scraping, and ensure originality. | High |
| Dynamically generated content with slight variations | Search engine might index multiple versions if the variations are substantial. | Use canonicalization tags to specify the preferred version. Optimize the dynamic content generation process. | Low to Medium |
Consequences of Duplicate Content
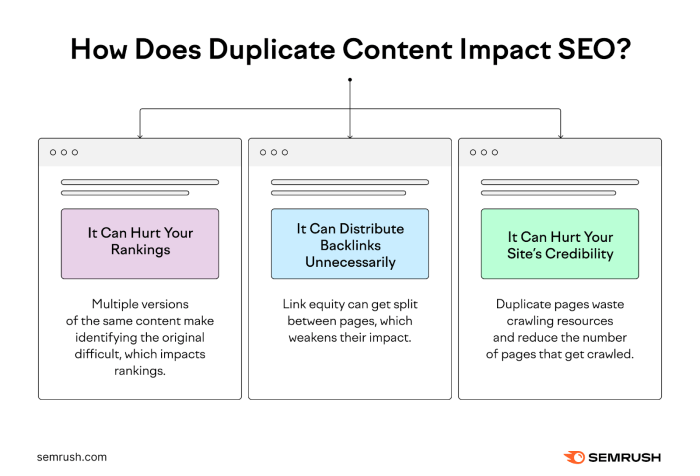
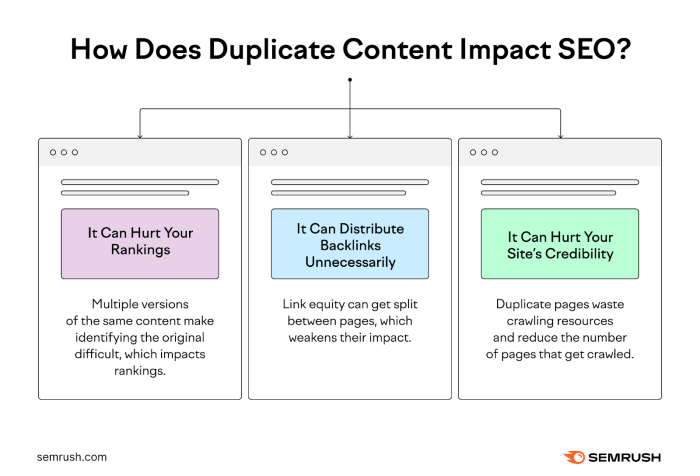
Duplicate content, while seemingly innocuous, can have severe repercussions for websites. It essentially dilutes a website’s authority and trustworthiness in the eyes of search engines and users. This dilution can manifest in various ways, impacting both search engine rankings and user experience. The penalties for duplicate content can range from minor ranking adjustments to complete removal from search results.Duplicate content is a significant concern because search engines prioritize unique, high-quality content.
When faced with multiple versions of the same information, search engines struggle to determine which version is most relevant and authoritative. This confusion can lead to negative consequences, potentially damaging a website’s online presence.
Negative Impacts of Duplicate Content
Duplicate content harms a website in several ways, often leading to reduced visibility and user engagement. The impact extends beyond simply losing search engine rankings, impacting the overall trustworthiness and credibility of the site.
- Reduced Search Engine Rankings: Search engines like Google employ sophisticated algorithms to identify and penalize websites with duplicate content. This results in lower rankings for the affected pages, making it harder for users to find the site through search results. For instance, a blog post published on a website with several similar articles could be penalized and rank lower in search results.
Websites with duplicate content are less likely to appear in search results.
- Penalty Imposition: Search engines may impose penalties on websites with significant duplicate content. These penalties can take various forms, including lower rankings, reduced visibility, or even complete removal from search results. A news website that republishes articles from other news sources without significant edits could face penalties.
- Damaged User Experience: Users expect unique and valuable content. Duplicate content frustrates users, who may perceive the website as unreliable or lacking in originality. This negative user experience can deter users from engaging further with the website, leading to decreased traffic and conversions. A user browsing a travel blog that has numerous articles with identical content will likely lose interest and look for alternative resources.
- Erosion of Website Reputation: Duplicate content can severely damage a website’s reputation. Search engines and users perceive a website with duplicate content as less trustworthy and credible. This perception can harm the site’s long-term viability, making it difficult to regain lost trust and credibility. A company’s online reputation can be affected by duplicate content, causing customers to lose faith in the company’s brand.
Consequences Table
The following table illustrates the various negative impacts of duplicate content, examples of each impact, strategies for mitigation, and severity levels.
| Negative Impact | Examples | Mitigation Strategies | Severity Level |
|---|---|---|---|
| Reduced Search Engine Rankings | Lower ranking in search results, decreased visibility, difficulty attracting organic traffic. | Identify and remove duplicate content, create unique and high-quality content, optimize content for relevant s. | Medium |
| Penalty Imposition | Manual actions, algorithmic penalties, reduced search visibility, complete removal from search results. | Thoroughly review website content, implement a robust content management system, use tools to identify duplicate content. | High |
| Damaged User Experience | Users perceiving the website as unreliable, lack of engagement, low user retention. | Provide unique and valuable content, improve website navigation, optimize for mobile-friendliness. | Medium |
| Erosion of Website Reputation | Loss of trust and credibility, reduced brand value, negative customer perception. | Focus on creating high-quality, unique content, address and resolve duplicate content issues, build positive user experiences. | High |
Technical Causes of Duplicate Content: Myths About Duplicate Content
Hidden duplicate content isn’t always obvious. Sometimes, it’s a technical hiccup behind the scenes that’s causing the problem. Understanding the technical reasons behind duplicate content is crucial for effective website optimization and search engine success. These issues often go unnoticed, leading to unwanted consequences.Often, technical errors result in duplicate content that search engines perceive as low-quality, potentially affecting rankings.
These errors can be subtle, hidden within the website’s code and structure, but their impact on can be significant. Identifying and resolving these technical issues is paramount to maintaining a healthy and well-performing website.
Common Technical Reasons
Technical errors often create duplicate content through unintended code duplication. Misconfigurations, improper use of server settings, and poorly implemented web technologies can all contribute to the problem. This includes mistakes in how URLs are structured, handled, or redirected. These issues can range from simple typos to more complex problems.
URL Structure Issues
Various URL structures can lead to duplicate content. For instance, if your website uses different URL formats for the same page, search engines may index them as separate pages, creating duplicate content. A common example is a page accessible through both a query string and without it. If your website is using pagination, improper implementation can cause duplicate content issues.
Without proper canonicalization, multiple URLs might point to the same content.
Server Configuration Errors
Server-side issues are another significant source of duplicate content. Incorrect configuration settings, like multiple redirects or caching mechanisms, can create duplicate versions of pages. For example, a server might generate different versions of a page based on the user’s browser or device, creating duplicate content. Similarly, misconfigured robots.txt files might lead to crawling issues. If your server handles requests in multiple ways, this might lead to different versions of the page appearing to search engines.
Poorly Implemented Web Technologies
Incorrect implementation of web technologies can result in duplicate content. For example, different versions of a webpage, like mobile-friendly versions or different layouts, can create duplicates. Also, dynamic content that is not correctly canonicalized can create duplicate content. Issues in how your website uses JavaScript, particularly if it alters the URL structure, can lead to multiple URLs for the same page.
Poorly coded website templates can also result in similar pages across different sections.
Diagnosing and Fixing Technical Issues
Diagnosing technical duplicate content issues requires a multi-faceted approach. First, thoroughly analyze the website’s structure and content. Next, use tools to identify duplicate content and crawl your website effectively. These tools can help you find hidden issues that are not apparent through a simple visual inspection. Furthermore, carefully review your server logs and configuration settings to pinpoint any errors or inconsistencies.
Look for patterns in the URLs that might be duplicated. This often involves looking at how the server handles requests, redirects, and caching. If necessary, consider professional help from specialists for more complex issues.
Troubleshooting Table
| Technical Cause | Common Symptoms | Troubleshooting Steps | Solutions |
|---|---|---|---|
| Multiple URLs for the same page | Different URLs display the same content | Use a site crawler to identify multiple URLs for the same page. Check server logs for unusual redirect patterns. | Implement a 301 redirect from the duplicate URLs to the canonical URL. |
| Server configuration issues (redirects, caching) | Duplicate content appearing due to redirect loops or caching problems. | Review server logs for unusual redirects. Inspect caching mechanisms and configurations. | Correct server configurations, ensure proper redirect chains, and optimize caching. |
| Poorly implemented web technologies (dynamic content, different layouts) | Duplicate content from dynamically generated pages, mobile-friendly versions, etc. | Use a browser developer tool to inspect the website’s HTML structure. Examine how JavaScript interacts with URLs. | Implement canonical tags and use proper parameters for different versions of the site. |
Content Strategy to Avoid Duplication
Preventing duplicate content is crucial for maintaining a healthy website and achieving optimal search engine rankings. Duplicate content, whether accidental or intentional, can significantly harm a website’s visibility and authority. Implementing a robust content strategy focused on originality and uniqueness is paramount for long-term success.A well-defined content strategy that prioritizes original content creation, mindful usage, and diverse content formats ensures that your website stands out and is favored by search engines.
This approach not only improves but also provides a more engaging user experience, leading to higher user satisfaction and loyalty.
Strategies for Unique Content Creation
Creating unique content requires a proactive approach and a commitment to originality. It involves more than simply rephrasing existing content; it demands a genuine effort to provide fresh perspectives, insights, and value to your audience.
- Conduct Thorough Research: Understanding the specific s your target audience uses is essential. Use research tools to identify relevant terms and phrases and incorporate them naturally into your content. Avoid stuffing, as this can negatively impact your and user experience. Focus on creating high-quality content that organically incorporates relevant s.
- Focus on Original Insights and Perspectives: Offer unique angles and analysis on topics that are already covered extensively. Don’t just summarize existing information; instead, provide your own interpretations, examples, and case studies to demonstrate a deeper understanding of the subject matter. This approach establishes your website as a valuable source of information.
- Utilize Diverse Content Formats: Employ various content formats such as blog posts, infographics, videos, podcasts, and interactive tools to cater to different learning styles and preferences. This diversification not only enhances user engagement but also signals to search engines that your website offers a wide range of valuable content.
Importance of Original Content for and User Engagement
Original content is paramount for both search engine optimization and user engagement. Search engines prioritize websites that provide unique and valuable content to users. This original content demonstrates a commitment to providing valuable information, leading to increased user engagement and loyalty.
- Search Engine Rankings: Search engines like Google use sophisticated algorithms to assess the quality and originality of content. Original content, rich in unique insights and perspectives, is more likely to rank higher in search results, driving organic traffic to your website. The value and originality of content are key factors for improved rankings.
- User Engagement: Unique content is more engaging and provides greater value to users. This leads to longer session durations, lower bounce rates, and increased user interaction with your website. Original content creates a more fulfilling experience for visitors, fostering loyalty and encouraging repeat visits.
Examples of Content Duplication Prevention Methods
Different types of content require specific strategies to ensure uniqueness. Consider these examples for various content formats.
| Content Type | Best Practices | Pitfalls | Strategies |
|---|---|---|---|
| Blog Posts | Conduct thorough research; focus on unique insights; use diverse content formats like images and videos | Rephrasing existing content; relying on low-quality content from other sources; stuffing | Use original research, expert interviews, and unique perspectives; rewrite content from your own unique point of view |
| Product Descriptions | Highlight unique product features and benefits; emphasize originality and value | Copying descriptions from competitors; using generic descriptions | Conduct detailed product research; create personalized descriptions tailored to your target audience; use specific details and illustrations |
| Website Copy | Craft original website copy; prioritize clarity and conciseness | Reusing content from other pages; using generic or cliché phrases | Develop a content calendar and Artikel; create original content; tailor content to specific landing pages; consider user experience and language style |
Duplicate Content and Internationalization
International websites face unique challenges in managing content, especially when catering to diverse audiences across different languages and regions. Translating website content directly often leads to substantial duplicate content issues. This can negatively impact search engine rankings and user experience. Understanding these challenges and implementing appropriate strategies is crucial for international success.Effective internationalization requires a careful balance between providing localized content and maintaining a coherent brand identity while avoiding duplicate content penalties.
This often involves adapting content strategically to specific regions and languages, without compromising the original content’s value.
Challenges of Handling Duplicate Content Across Languages and Regions
International websites often struggle with the proliferation of nearly identical content in different languages. This is often a result of direct translations, leading to duplicated content across multiple language versions. Furthermore, cultural nuances and local requirements often necessitate alterations to content, which further complicates the issue. The result can be a complex web of almost identical content spread across different URLs, negatively impacting .
Strategies for International Websites to Avoid Duplicate Content Issues
A critical strategy for avoiding duplicate content issues in internationalized websites is the use of dynamic content adaptation. This allows for different versions of a single page to be generated based on the user’s locale, without creating separate, static pages for each language. Another key strategy involves using canonical tags effectively to specify the primary version of the content.
These strategies ensure that search engines correctly identify the original content and avoid penalizing the site for duplicate content.
Common Issues and Solutions for Internationalized Sites
A frequent issue is creating entirely separate pages for each language version, leading to duplicate content and diluted value. A solution is to employ dynamic content generation that produces localized versions of a single page. Another common issue is the lack of appropriate hreflang tags, which signal to search engines the correct language and regional version of a page.
Implementing hreflang tags is crucial for preventing search engines from treating different language versions as separate, duplicate pages.
So, you’ve heard the whispers about duplicate content? It’s a common misconception that if you just copy and paste, search engines will punish you. Actually, understanding how search engines work is key. A good SEO consultant can help you navigate these waters, ensuring your content is unique and valuable to users. A solid SEO strategy, crafted by someone like what is an seo consultant , means avoiding these myths and focusing on creating compelling, original content that benefits both your readers and the search engines.
The truth is, search engines are much smarter than you think!
Importance of Using Appropriate Hreflang Tags
Hreflang tags are crucial for informing search engines about the relationship between different language versions of a page. They allow search engines to correctly identify the most appropriate version of a page for a given user’s location and language. This is vital for preventing duplicate content issues and ensuring that the correct version of the content appears in search results.
Incorrect or missing hreflang tags can lead to significant penalties and a confusing user experience.
Example Table of Hreflang Tag Implementation
| Language | Country | Content Adaptation | Appropriate Hreflang Tags |
|---|---|---|---|
| English | United States | Original content, no adaptation needed. | <link rel=”alternate” href=”https://example.com/” hreflang=”en-US”> |
| Spanish | Spain | Translated content, adapted for Spanish audience. | <link rel=”alternate” href=”https://example.com/es/” hreflang=”es-ES”> |
| French | France | Translated content, adapted for French audience, different address structure. | <link rel=”alternate” href=”https://example.com/fr/” hreflang=”fr-FR”> |
| German | Germany | Translated content, adapted for German audience, different address structure. | <link rel=”alternate” href=”https://example.com/de/” hreflang=”de-DE”> |
Duplicate Content and Dynamic Content
Dynamic content, generated on the fly, is a common feature in modern websites. While offering significant advantages in terms of personalization and flexibility, it can inadvertently lead to duplicate content issues. Understanding how dynamic content can create duplicates and implementing strategies to prevent them is crucial for maintaining a strong search engine presence and a positive user experience.Dynamic content, in essence, is content that changes based on user input, parameters, or other variables.

This can range from simple filtering options to complex e-commerce product listings. While this adaptability is beneficial, it often results in multiple URLs displaying near-identical content. This is particularly problematic for search engines, as they might index these similar pages as duplicates, potentially impacting search rankings.
Dynamic Content and Duplicate Content Issues
Dynamically generated content can lead to significant duplicate content problems. This occurs because many systems create multiple pages with virtually identical content, only differing slightly in the parameters. Search engines, designed to present unique, relevant content, can struggle to distinguish between these nearly identical pages, often indexing them as duplicates. This can result in diluted search engine rankings for the website.
It’s important to recognize the inherent challenges and implement solutions to mitigate these issues.
Handling Dynamic Content and Avoiding Duplication
Several methods can be used to address duplicate content issues arising from dynamic content. These solutions vary depending on the specific system and the nature of the content.
Debunking myths about duplicate content is crucial for SEO success. Many believe Google penalizes identical content across sites, but that’s often inaccurate. Understanding Google’s culture of success, googles culture of success , reveals a more nuanced approach. Ultimately, focusing on quality, user experience, and providing unique value is key to ranking well, not just avoiding duplicate content issues.
- Canonicalization: A crucial technique to address dynamic content duplication is using canonical tags. These tags instruct search engines which version of a page is the authoritative one, thereby preventing indexing of duplicate content. This is a crucial step in managing dynamic content. Using canonical tags correctly is vital for preventing duplicate content penalties from search engines.
- URL Parameters Removal: Another approach is removing unnecessary URL parameters that contribute to the generation of duplicate content. This approach often involves redirecting users to a clean URL without these parameters. This approach involves redirecting the user to a canonical version of the page. For example, removing session IDs or pagination parameters from URLs can greatly reduce duplicate content issues.
- Content Delivery Networks (CDNs): CDNs can also play a role in managing dynamic content and reducing duplicate content issues. By caching dynamic content, CDNs can improve page loading speed while also potentially reducing the number of duplicate URLs generated.
- Database Optimization: Optimizing the database used to generate dynamic content is also important. For instance, ensuring that only unique data is fetched and displayed can reduce the number of nearly identical pages.
Examples of Dynamic Content Generation Systems and Issues
E-commerce sites often generate numerous product pages dynamically, each differing slightly in the product ID or filter applied. This can lead to a significant number of duplicate URLs. Similarly, blog search results pages, and dynamically generated pagination, can present duplicate content problems. Blog search pages, if not carefully managed, can result in duplicated content from the search results.
Preventing Duplicate Content in Dynamic Environments
A multifaceted approach is crucial for preventing duplicate content issues in dynamic environments. This includes careful planning, efficient coding practices, and robust validation of generated URLs. Implementing a consistent structure and using canonical tags are paramount for managing dynamic content and preventing issues. These strategies will ensure a positive user experience and high search engine rankings.
Table: Dynamic Content Scenarios, Challenges, Solutions, and Best Practices
| Scenario | Challenges | Solutions | Best Practices |
|---|---|---|---|
| E-commerce product listings | Numerous product pages with slight variations (e.g., different filters, sorting). | Canonicalization, URL parameter removal, robust filtering logic. | Maintain a single canonical URL for each product. |
| Blog search results | Multiple pages for search results based on different s. | Canonicalization, redirecting to the main blog page, pagination management. | Use pagination properly to avoid duplicated content and maintain a clear structure. |
| Dynamic content with parameters | Parameters in URLs create numerous similar pages. | Canonicalization, parameter removal through redirects. | Prioritize canonical URLs and use redirects to manage dynamic parameters. |
| News aggregator sites | Numerous articles with identical or similar content from different sources. | Canonicalization, robust content filtering, and cross-referencing. | Prioritize the source and date to determine the most valuable content. |
Duplicate Content and Canonicalization

Duplicate content is a significant concern, and search engines penalize websites with identical or near-identical content. Canonicalization is a crucial technique to combat this problem, guiding search engines to the preferred version of a page. Properly implemented canonical tags help avoid penalties and ensure that search engines index the desired version of your content.Canonicalization is the process of specifying the single, definitive URL for a piece of content.
Search engines use this information to understand which version of a page is the original and most authoritative. By using canonical tags, website owners can indicate to search engines which URL should be considered the primary version of a page, preventing duplicate content issues and directing search engine crawlers to the right source.
Understanding Canonical Tags
Canonical tags are HTML elements that tell search engines which URL is the preferred version of a web page. They are a vital part of a robust strategy, helping maintain a positive search ranking.
Implementing Canonical Tags Effectively
The correct implementation of canonical tags is crucial for avoiding duplicate content penalties. Here’s how to implement them effectively:
- Placement: Canonical tags are typically placed in the ` ` section of the HTML document.
- Syntax: The canonical tag uses the ` ` element with a specific `rel` attribute and `href` attribute. The `rel=”canonical”` attribute clearly identifies the tag as a canonical link. The `href` attribute specifies the canonical URL.
- Accuracy: The canonical URL must be precise and point to the intended preferred version of the page. Errors in the canonical URL can lead to search engine confusion and potentially negative ranking effects.
- Consistency: Ensure the canonical URL is consistent across all versions of a page, including mobile and desktop versions.
Examples of Canonical Tag Implementations
Here are several examples demonstrating different scenarios for canonical tag implementation:
| Scenario | Canonical Tag Implementation |
|---|---|
| Redirecting a duplicate page | `` |
| Handling pagination | `` (for the first page) ` ` (for the second page, if different content) ` ` ` ` |
| Managing different language versions | `` (for the English version) ` ` (for the French version) |
Importance of Setting the Correct Canonical URL
Choosing the correct canonical URL is paramount to preventing duplicate content issues. A precisely set canonical URL ensures search engines understand the authoritative version of a page.
Demonstrating Canonicalization in Action
Imagine a website with a blog post available on both desktop and mobile versions. By using canonical tags, the website can point search engines to the desktop version as the primary source. This ensures that the desktop version is indexed, preventing search engines from indexing and penalizing the mobile version. This, in turn, helps maintain a positive search ranking and avoid the negative impact of duplicate content.
Duplicate Content and Redirects
Duplicate content can significantly harm your website’s search engine ranking and user experience. One crucial strategy to mitigate this issue is the proper implementation of redirects. Redirects are essentially instructions that tell search engines and users to move from one URL to another. When used correctly, they can effectively handle duplicate content, preserving valuable backlinks and maintaining a seamless user journey.Redirects are essential for managing duplicate content effectively, preserving valuable search engine rankings and ensuring a smooth user experience.
Using appropriate redirects is crucial to ensure that search engines and users are directed to the correct, non-duplicate version of your content.
Choosing the Right Redirect Type
Redirects come in various types, each with its own purpose and implications. Understanding the different types is essential for selecting the most suitable redirect for your specific scenario.
- 301 Permanent Redirects: These are the most common and suitable choice when a URL is permanently changed. A 301 redirect tells search engines that the target URL has permanently moved to a new location. This is crucial for preserving search engine rankings, as the authority and link equity from the old URL are transferred to the new one.
- 302 Temporary Redirects: These are used when a URL is temporarily moved, for instance, during site maintenance or a promotional campaign. Search engines generally treat the authority of the old URL as less valuable for the new URL compared to a 301.
- Meta Refresh Redirects: These are client-side redirects, meaning the redirection happens on the user’s browser. They’re less common and generally not recommended for purposes. They might not be effectively picked up by search engines.
Implementing 301 Redirects, Myths about duplicate content
Implementing 301 redirects involves configuring your web server to automatically send users and search engines to the new URL when they access the old one. This is a crucial step for preserving your website’s value.
- Identify Duplicate Content URLs: Thoroughly analyze your website to pinpoint all instances of duplicate content. This involves crawling your site and using tools to identify overlapping content.
- Determine the Canonical URL: Select the definitive, non-duplicate version of your content. This will be the URL that receives all the value.
- Configure the Redirect: Utilize your web server’s configuration (e.g., .htaccess file for Apache, web server settings for Nginx) to implement the 301 redirect. This typically involves creating a rule that directs traffic from the old URL to the new one.
- Verify the Redirect: Use a tool like Google Search Console or a dedicated redirect checker to confirm that the redirect is working correctly and that the 301 status code is being returned. Regularly monitoring is essential.
Redirect Scenarios and Solutions
Choosing the correct redirect type is crucial for maintaining search engine rankings and user experience. The table below illustrates various redirection scenarios with their recommended solutions.
| Scenario | Redirect Type | Benefits | Implementation |
|---|---|---|---|
| A product page URL has been changed | 301 Permanent Redirect | Preserves search engine rankings, maintains user experience. | Configure a 301 redirect from the old URL to the new product page URL. |
| A blog post is being archived and no longer active. | 301 Permanent Redirect | Maintains value for the archive, avoids broken links. | Redirect the old URL to an appropriate archive page. |
| A landing page is updated and needs to be redirected to the new version. | 301 Permanent Redirect | Preserves value and maintains the user journey. | Redirect the old landing page URL to the updated one. |
| A website is undergoing a redesign. | 301 Permanent Redirect | Preserves value during the transition. | Redirect all old URLs to their corresponding new versions on the redesigned site. |
Closing Summary
In conclusion, understanding the myths surrounding duplicate content is crucial for website success. By debunking these misconceptions and implementing the strategies Artikeld in this guide, you can ensure your website maintains a strong online presence, optimized for search engines and user engagement. This knowledge empowers you to create a seamless and valuable experience for your visitors, ultimately fostering a positive relationship with your audience.

