
Googles advice on fixing unwanted indexed urls – Google’s advice on fixing unwanted indexed URLs provides a comprehensive guide to understanding, identifying, and resolving unwanted web pages in Google’s index. This guide covers everything from Google’s indexing process to effective removal strategies and future prevention techniques.
The article delves into the intricate process of how Google indexes web pages, explaining the factors influencing ranking and prioritization. It also details methods for identifying unwanted indexed URLs, including utilizing Google Search Console. Furthermore, it explores Google’s official removal guidelines, different removal methods, and the timeframe for processing requests. This detailed analysis also covers strategies to prevent future indexing issues and alternative solutions for content that cannot be removed, such as managing duplicate content and using redirects.
Understanding Google’s Indexing Process: Googles Advice On Fixing Unwanted Indexed Urls
Google’s search engine is a complex system, but at its core, it’s about understanding and organizing the vast amount of information available on the web. This process, called indexing, allows users to quickly find relevant content. This involves a series of steps, from discovery to ranking, that ensure users can find what they need efficiently.Google’s indexing process is a dynamic and ongoing operation.
It constantly updates its database of web pages to reflect changes and new content. Understanding how this process works helps you optimize your website for better visibility and improved search engine rankings.
Google’s Web Page Discovery Methods
Google discovers web pages through various methods. One primary method is through crawling, where Google’s web crawlers, often called spiders, follow links from one page to another, discovering new content. These crawlers are sophisticated programs that can navigate complex websites and identify relevant information. Another significant method involves submissions to Google Search Console, where website owners can directly notify Google about new or updated content.
This allows for quicker indexing of new pages or changes. Finally, Google also utilizes user interactions, such as clicks and searches, to identify trending topics and potentially important content.
Google’s Web Page Crawling Process
Google’s web crawlers follow a methodical process. They begin by prioritizing websites based on factors like their popularity and previous crawl frequency. Once a page is selected, the crawler downloads the HTML code. The crawler then analyzes the HTML, extracting text, links, and other relevant information. This process is crucial for understanding the content and structure of the web page.
Subsequently, the crawler follows links to other pages within the site and external sites, further expanding its understanding of the web. The crawlers are designed to handle large volumes of data and rapidly navigate the internet.
Factors Affecting Page Ranking and Prioritization
Various factors influence how Google ranks and prioritizes pages. These factors are multifaceted and continuously evolving to ensure relevance and user experience. Page content, quality, and authority are key considerations. High-quality content, written with clarity and focus on user needs, tends to rank higher. The authority of the website, determined by factors like backlinks from reputable sources, also impacts ranking.
Technical aspects, such as website speed and mobile-friendliness, are also critical, as Google prioritizes user experience. Finally, user engagement, such as click-through rates and time spent on the page, provides signals to Google about the relevance and value of the content.
Google’s Index Structure
Google’s index is a massive database of web pages. It’s structured in a complex way to facilitate fast searching. Each web page is indexed with details about its content, including s, links, and other metadata. This structured data allows Google to efficiently retrieve relevant results when users perform searches. The index is constantly updated to reflect changes and new information on the web.
This dynamic nature ensures that Google’s search results remain current and relevant.
Indexing Process Summary
| Process Step | Description | Impact on Indexing |
|---|---|---|
| Discovery | Google discovers web pages through various methods, including crawling, submissions, and user interactions. | Determines the initial visibility of a page to Google’s crawlers. |
| Crawling | Google’s web crawlers systematically download and analyze web pages, extracting text, links, and other information. | Enables Google to understand the content and structure of web pages. |
| Indexing | Google stores the extracted information in its massive index, linking it to relevant s and other data. | Makes the information searchable and retrievable by users. |
| Ranking | Google uses various factors to rank pages in search results, considering content quality, authority, technical aspects, and user engagement. | Determines the position of a page in search results, impacting its visibility and traffic. |
Identifying Unwanted Indexed URLs
Unwanted indexed URLs can significantly impact your website’s and user experience. These are pages that, for various reasons, shouldn’t be visible in search results. Identifying and addressing these URLs is crucial for maintaining a clean and effective online presence. Knowing how to pinpoint these pages and understand their implications is essential for any website owner or professional.Understanding that Google’s index is a dynamic reflection of your website’s content, identifying these unwanted URLs requires a systematic approach that combines technical analysis with a keen understanding of your site’s structure and purpose.
Google’s advice on fixing unwanted indexed URLs often revolves around using canonical tags. These tags tell search engines which version of a page is the definitive one, helping to avoid duplicate content issues. By implementing the correct canonical tags, you can guide Google to the preferred version of your pages, effectively resolving the problem of unwanted URLs being indexed.
Understanding how to use what are canonical tags is crucial for effectively managing your site’s indexing within Google’s algorithm. This ultimately streamlines the process of fixing those unwanted indexed URLs and ensures a better user experience.
A thorough approach to this task ensures that your website is represented accurately in search results.
Methods for Discovering Unwanted URLs
Identifying unwanted indexed URLs involves employing several techniques. The first step is to recognize the difference between a page that should not be indexed and a page that is simply not performing well. Unwanted URLs might include duplicate content, low-value pages, pages in development, or pages that are simply outdated or no longer relevant to your site’s purpose.
- Manual Inspection: Carefully review your website’s content. Look for pages that seem out of place, are not optimized, or have little to no value to users. Consider the purpose of each page and whether it aligns with your overall site strategy. A clear understanding of the website’s content hierarchy and the purpose of each page will help identify unwanted content.
- Using Google Search Console: Google Search Console provides valuable insights into your website’s indexed pages. It’s a powerful tool for identifying unwanted URLs. Look for pages with low or no click-through rates, or those that are frequently flagged for issues by search engines. Using Search Console, identify pages with crawl errors or pages that Google is struggling to understand.
- Content Analysis Tools: Employ tools that assess the quality and relevance of your website’s content. These tools can identify duplicate content, thin content, and other issues that might contribute to unwanted indexing. Analyze the structure of the content and whether it fits the website’s theme.
Techniques for Identifying Low-Value or Duplicate Content
Low-value and duplicate content can lead to unwanted indexing. These pages typically don’t offer much benefit to users and can negatively impact your site’s overall performance.
- Duplicate Content Detection Tools: Utilize tools specifically designed to detect duplicate content across your website and against external sources. Compare your website’s content with other websites to find identical or nearly identical pages. This comparison helps identify pages that are not original or unique, thus leading to indexing problems.
- Analyzing Page Structure and Content: Analyze the structure and content of each page to assess its value and uniqueness. Look for pages with minimal text, low-quality images, or repetitive information. Evaluate the content’s value to the reader, as well as its originality.
Using Google Search Console for Unwanted Indexed URL Identification
Google Search Console is a critical tool for identifying unwanted indexed URLs. It provides comprehensive data about your website’s presence in Google’s index.
- Crawl Errors Report: This report lists pages that Google encountered issues with during the crawling process. These errors might indicate issues with the page’s structure, which can lead to unwanted indexing. It is important to note that these crawl errors can affect the indexing of the page.
- Indexed Pages Report: Review the list of indexed pages. Identify those that aren’t relevant to your website’s goals or don’t provide value to users. This report is crucial to understand what pages are currently indexed by Google.
Crawl Errors vs. Unwanted Indexed URLs
Crawl errors and unwanted indexed URLs are distinct but related issues.
| Feature | Crawl Errors | Unwanted Indexed URLs |
|---|---|---|
| Definition | Errors encountered by Googlebot during the crawling process. | Pages indexed by Google, but not desired to be visible in search results. |
| Impact | Can prevent Google from fully understanding or indexing the page. | Can negatively affect and user experience. |
| Resolution | Fixing the underlying technical issues on the page. | Removing or disallowing the pages from indexing. |
Flowchart for Identifying Unwanted Indexed URLs
A flowchart to help in the identification process:
(Insert a visual flowchart here illustrating the steps. The flowchart should include steps like inspecting website content, checking Google Search Console, analyzing content quality, identifying duplicate content, and resolving crawl errors.)
Google’s Methods for Removing URLs from Index
Google’s search index is vast and constantly evolving. Maintaining accuracy and relevance is crucial. Unwanted or outdated content can negatively impact a website’s visibility and user experience. Understanding how to effectively remove URLs from Google’s index is vital for website optimization. This guide delves into Google’s official guidelines and strategies for removing unwanted indexed URLs.Effectively removing unwanted URLs from Google’s index requires a precise understanding of Google’s processes.
This involves correctly identifying the problematic URLs and employing the appropriate removal methods. This section provides a detailed overview of Google’s methods for removing URLs, enabling website owners to efficiently address unwanted content and improve their search engine visibility.
Google’s Official Guidelines for URL Removal
Google’s guidelines for URL removal requests are specific and aim to balance the need for content removal with maintaining the integrity of its search index. They emphasize that removal requests are not guaranteed, and success depends on various factors, including the nature of the content and Google’s evaluation of the request.
Examples of Removal Request Types, Googles advice on fixing unwanted indexed urls
Different scenarios necessitate different types of removal requests. Examples include:
- Removing outdated or irrelevant content: A blog post about a discontinued product, an outdated service, or an event that has passed.
- Removing content with duplicate information: Content that mirrors existing pages or articles, often due to a site migration or redesign.
- Removing content with factual errors or inaccuracies: Information that is inaccurate, misleading, or harmful.
- Removing content that violates Google’s policies: This can include content that is spammy, infringes on copyright, or promotes illegal activities.
Methods Google Accepts for Removal
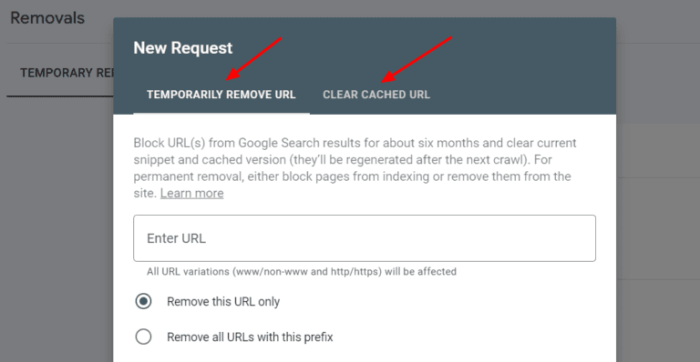
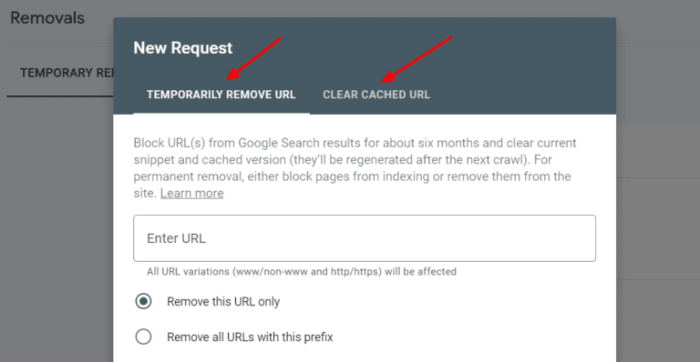
Google accepts various methods for removal requests. The most common approach is through a dedicated removal request form. However, there are other situations where a specific method might be more suitable.
- Removal Request Form: This is the most common method, using Google Search Console. It involves submitting a formal request with details about the URL.
- Disavow Tool: While primarily used for removing backlinks, the disavow tool can indirectly impact indexing by targeting links from low-quality or malicious sites that may lead to a particular page.
- Contacting Google Webmasters: In specific, complex situations, direct communication with Google Webmasters can be beneficial. This method is usually reserved for issues that fall outside of the typical removal request form.
Timeframe for Processing Removal Requests
The time it takes for Google to process removal requests varies. There’s no set timeframe. Factors such as the volume of requests, the nature of the content, and Google’s internal processing can influence the response time. Google typically responds within a few weeks, though it can sometimes take longer.
Strategies for Requesting Removal and Their Success Rates
Different strategies for submitting removal requests can impact their success rate. Crafting a concise, accurate, and compelling request can significantly increase the chances of success.
- Detailed and specific descriptions: A well-articulated request that clearly Artikels the reason for removal significantly improves the likelihood of a successful outcome.
- Adherence to Google’s guidelines: Requests that align with Google’s policies and guidelines have a higher chance of being approved.
- Providing supporting documentation: In cases of factual errors or violations, providing evidence or documentation can strengthen the request. This approach is more successful when the violation is clear.
Comparison of Removal Methods
| Method | Description | Success Rate | When to Use |
|---|---|---|---|
| Removal Request Form (Google Search Console) | Formal request via Google Search Console | High, if request is well-articulated | Most common, for most types of removals |
| Disavow Tool | Removes potentially harmful backlinks | Moderate, indirect impact on indexing | For issues with spammy or malicious links affecting a page |
| Contacting Google Webmasters | Direct communication with Google | High, for complex cases | Reserved for unusual or complex situations |
Preventing Future Indexing Issues
Preventing unwanted URLs from being indexed by Google is crucial for maintaining a clean and accurate online presence. A well-structured website, with careful attention to technical aspects, is the key to avoiding future indexing problems. This involves understanding common pitfalls and employing proactive strategies to keep your site’s desired content visible and unwanted content hidden from search results.
Strategies to Avoid Unwanted Indexing
Effective strategies to prevent unwanted indexing involve proactive measures to control how search engines crawl and index your website. This includes meticulous planning of site architecture, content creation, and technical implementation. By adhering to best practices, you can ensure that your desired content is prioritized, while unwanted content is excluded from search results.
Common Mistakes Leading to Unwanted Indexing
Several common mistakes can lead to unwanted content being indexed. These mistakes often stem from oversight in technical implementation or a lack of understanding of how search engines operate. Knowing these mistakes helps you avoid them and ensure your site remains optimized for search.
- Missing or Incorrect Robots.txt Directives: Failing to specify which pages should not be indexed, or using incorrect directives, allows search engine crawlers to index unwanted content. This can lead to duplicate content issues and negatively impact .
- Duplicate Content Issues: Creating multiple versions of the same content on your site, or copying content from other sites, can confuse search engines and lead to indexing problems. Search engines prioritize unique content.
- Poor Site Structure and Navigation: A poorly structured website makes it difficult for search engines to understand the hierarchy and importance of different pages. This can lead to irrelevant pages being indexed and important pages being overlooked.
- Incorrect Use of Canonical Tags: Misusing canonical tags can confuse search engines about the primary version of a page, leading to duplicate content penalties. This is a significant error impacting indexing and .
- Dynamically Generated Content without Proper Caching or Pagination: Dynamic content that changes frequently or lacks proper pagination and caching mechanisms can lead to a large number of indexed URLs, some of which may not be valuable.
Importance of Proper Sitemaps and Robots.txt Files
Sitemaps and robots.txt files are essential tools for controlling how search engines crawl and index your website. A well-structured sitemap helps search engines understand the structure of your site, while robots.txt instructs them on which pages to crawl and which to avoid.
- Robots.txt File: A robots.txt file acts as a guide for search engine crawlers. It instructs them which parts of your website they should not crawl, preventing unwanted pages from being indexed. A carefully crafted robots.txt file helps you control the scope of indexing.
- Sitemap File: A sitemap file lists all the important pages on your website. It allows search engines to easily find and index the pages you want them to see. A well-structured sitemap improves the indexing process and helps search engines understand the site’s structure.
Correct Use of Canonical Tags
Canonical tags are essential for managing duplicate content issues. They tell search engines which version of a page is the primary one, preventing indexing of duplicate or redundant content.
Effective Site Architecture to Prevent Unwanted Indexing
Effective site architecture plays a significant role in preventing unwanted indexing. A well-organized site structure helps search engines understand the hierarchy of your content and prioritizes the pages you want indexed.
| Mistake | Explanation | Prevention Strategy |
|---|---|---|
| Missing or Incorrect Robots.txt Directives | Search engines crawl and index pages they shouldn’t, leading to duplicate content and poor . | Create a robots.txt file to explicitly tell search engines which pages to ignore. |
| Duplicate Content Issues | Multiple versions of the same content confuse search engines, leading to penalties. | Use canonical tags to specify the primary version of a page. |
| Poor Site Structure and Navigation | Difficult for search engines to understand the site’s hierarchy, leading to irrelevant pages being indexed. | Implement a clear site structure with logical navigation. |
| Incorrect Use of Canonical Tags | Misuse of canonical tags confuses search engines about the main version of a page. | Ensure correct implementation of canonical tags pointing to the correct primary page. |
| Dynamically Generated Content without Proper Caching or Pagination | Unwanted content can be indexed if proper caching or pagination is not implemented. | Implement proper caching mechanisms and pagination for dynamically generated content. |
Alternative Solutions for Unwanted Indexed Content
Sometimes, despite our best efforts, certain pages remain indexed by Google despite our attempts to remove them. This section Artikels alternative strategies for managing these persistent listings, focusing on content that cannot be directly removed from the index. These methods aim to mitigate the impact of unwanted content on search results and user experience.Dealing with unwanted indexed content that can’t be immediately removed requires a multifaceted approach.
It’s not about deleting the content entirely, but rather about influencing how Google perceives and ranks it within its search results. We’ll explore techniques for managing duplicate content, low-value pages, and using redirects to improve the user experience and reduce the negative impact of these listings.
Managing Duplicate Content
Duplicate content is a common issue that can negatively affect search rankings. Search engines prioritize unique, original content. Identifying and addressing duplicate content is crucial to improve search visibility and avoid penalties. Duplicate content can arise from unintentional copying, mirroring of content across different domains, or even simple variations in URL structures.

Google’s advice on fixing unwanted indexed URLs is super helpful, but sometimes you need a broader strategy. Learning how to write compelling blog posts is crucial for SEO success. Improving your writing skills, like mastering different writing styles or understanding keyword research, can significantly impact your blog’s visibility. how writers improve blogging skills can help you refine your approach, which ultimately makes fixing those unwanted indexed URLs much easier.
Understanding user engagement and creating content that truly resonates with your target audience is key to long-term success, ultimately aligning with Google’s indexing guidelines.
- Canonicalization: Using the rel=”canonical” tag helps Google understand the primary version of a piece of content, thereby preventing duplicate content penalties. This tag tells search engines which URL represents the definitive version of a page. A well-implemented canonical tag helps Google correctly index and rank the page, reducing the impact of duplicate content. For example, if you have the same content on multiple pages, you would use the canonical tag to indicate which one is the original and should be indexed.
- Content Differentiation: If you can’t fully remove duplicate content, focus on making the content distinct. Adding unique text, images, or other media can help Google perceive it as separate content, thereby improving its visibility. Using different layouts, adding unique metadata, or modifying the content slightly to add value will help improve the perception of the duplicate content.
Handling Low-Value Pages
Low-value pages often include thin content, outdated information, or pages with minimal user engagement. They can negatively impact a website’s overall search visibility. Strategies to handle low-value pages involve prioritizing content updates and improvements.
- Content Improvement: Updating or improving the content on low-value pages to increase their quality and relevance is often the most effective solution. Focus on providing valuable and unique information to users. Consider adding more depth, improving formatting, or adding more relevant s to improve the quality of the content. Adding more detail to the content to make it more engaging and informative will also help.
Google’s advice on fixing unwanted indexed URLs is pretty straightforward, but sometimes it’s a pain to track down the culprit. Fortunately, keeping an eye on your Google Ads performance is crucial, and the recent addition of 3 new reporting columns in Google Ads might help you spot issues early. Ultimately, understanding why certain pages are indexed and how to fix them is key to a healthy website, so focusing on Google’s recommended fixes is still the best long-term strategy.
- Redirection: Redirecting users to more relevant pages is a viable alternative. This approach redirects users to more valuable content on the website, preventing the negative impact of low-value pages. For example, if a page has outdated information, you could redirect users to a more current version of the page or a new page that contains the same information but in a more relevant format.
Using Redirects for Unwanted Indexed URLs
Redirects are a powerful tool for managing unwanted indexed URLs. They essentially tell search engines and users to move to a different location. Properly implementing redirects is essential to maintain user experience and search engine visibility.
| Redirect Type | Description | Effectiveness |
|---|---|---|
| 301 Redirect | Permanent redirect. Indicates that the content has permanently moved to a new location. | Highly effective for maintaining value. |
| 302 Redirect | Temporary redirect. Indicates that the content is temporarily moved. | Less effective for , used for temporary situations. |
| Meta Refresh Redirect | A client-side redirect that tells the browser to redirect the user to another page. | Can be effective, but not as robust as server-side redirects. |
Content Quality and Relevance
High-quality, relevant content is the cornerstone of a successful website. Creating content that satisfies user needs and aligns with search intent is crucial to prevent unwanted indexing in the future. Content should be unique, informative, and valuable to users.
“Prioritizing content quality and relevance is the most effective long-term solution for avoiding unwanted indexed content. Focusing on user needs and providing value will result in higher search rankings and a more positive user experience.”
Case Studies and Examples

Dealing with unwanted indexed URLs requires understanding real-world scenarios. This section provides case studies, illustrating common indexing issues and successful strategies for resolution. We’ll explore examples of how different approaches affect search visibility and how to prevent similar problems in the future.
Real-World Examples of Unwanted Indexing Issues
Unwanted indexing can stem from various sources. One common issue arises from dynamically generated content. A website might unintentionally index numerous URLs that result from user interactions or complex search parameters. Another issue is the indexing of outdated or temporary content. For example, promotional pages or product listings that are no longer active can remain in Google’s index, creating a negative impact on the site’s overall performance.
Additionally, pages with minor errors or incomplete content can sometimes be indexed, appearing in search results with limited or confusing information.
Successful URL Removal Requests and Strategies
Effective URL removal requests rely on clear communication and understanding of Google’s processes. Providing concise and accurate information about the URLs is crucial. Using the appropriate tools and channels for submitting removal requests, like Google Search Console, is essential. For instance, a clear explanation of why the content is no longer relevant, including the date of removal or update, significantly increases the likelihood of successful removal.
Specific examples of URLs, alongside concise explanations, are often more effective than vague descriptions.
Case Studies Demonstrating the Impact of Various Solutions
Several strategies can effectively manage unwanted indexing. One common method is using robots.txt to block crawlers from accessing specific URLs. This is particularly useful for preventing the indexing of temporary or dynamically generated content. A second method involves utilizing the Google Search Console’s URL removal tool. This allows for direct requests to remove specific URLs from the index, often yielding faster results for pages with clearly defined reasons for removal.
Implementing these strategies often leads to improvements in search visibility by removing irrelevant content from search results.
Steps Involved in Each Case Study
A well-structured approach involves the following steps:
- Identifying the unwanted URLs: Analyze search results and identify URLs that need removal.
- Understanding the cause of indexing: Determine if the content is outdated, dynamically generated, or contains errors.
- Choosing the appropriate removal method: Select the best approach, either robots.txt, Google Search Console, or a combination.
- Preparing the removal request: Provide a clear explanation of why the content should be removed, including specific URLs and reasons.
- Monitoring the results: Track the removal process and assess its impact on search results.
Summary Table of Case Studies
| Case Study | Issue | Solution | Outcome |
|---|---|---|---|
| Case 1 | Outdated product listings indexed | Google Search Console removal request with clear explanation | Successful removal of outdated listings from search results |
| Case 2 | Dynamically generated URLs with no value | robots.txt implementation blocking crawler access | Significant reduction in unwanted URLs indexed |
| Case 3 | Temporary promotional pages indexing | Combination of Google Search Console and robots.txt | Effective removal of temporary pages, improved search results |
Final Wrap-Up
In conclusion, understanding and addressing unwanted indexed URLs is crucial for website optimization. This comprehensive guide equips you with the knowledge and tools to effectively manage your website’s presence in Google’s index. By understanding Google’s indexing process, identifying unwanted URLs, utilizing removal methods, and preventing future issues, you can ensure your website’s visibility and performance align with your goals.

