Generative information retrieval search is revolutionizing how we find information. Instead of simply returning documents related to a query, this approach uses generative models to create new, relevant snippets of information. This innovative method promises to enhance user experience by providing more comprehensive and insightful results, potentially transforming the way we interact with information.
This exploration dives deep into the mechanics, strategies, and evaluation of generative information retrieval search, covering everything from the types of generative models used to the challenges in developing and implementing these systems. We will also examine the user interface design and integration with existing search engines.
Defining Generative Information Retrieval Search
Generative information retrieval (GIR) search is a revolutionary approach to finding information, moving beyond the limitations of traditional -based systems. Instead of simply matching queries to pre-existing documents, GIR leverages powerful generative models to create entirely new, relevant content tailored to the user’s needs. This approach promises a more intuitive and comprehensive information experience, transforming how we access and interact with data.This innovative method fundamentally alters the information retrieval paradigm.
Traditional methods rely on identifying documents containing relevant s. GIR, in contrast, uses generative models to synthesize novel information directly answering user queries, thus overcoming the limitations of static document collections. This dynamic and adaptive approach provides users with a more insightful and comprehensive understanding of the subject matter.
Key Characteristics of Generative Information Retrieval
GIR distinguishes itself from traditional retrieval methods by its inherent ability to generate new information. This contrasts with traditional methods that primarily focus on retrieving existing documents that match a query. This inherent capacity to produce novel responses enables the system to address complex queries or provide insights beyond the scope of existing data.
Role of Generative Models
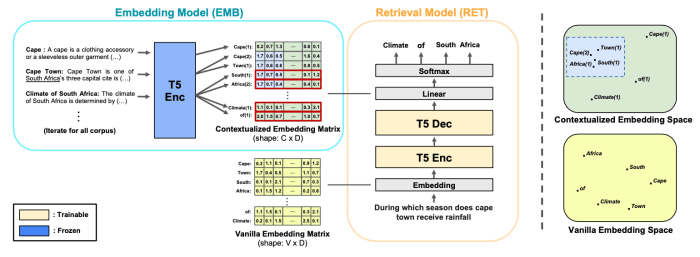
Generative models, such as large language models (LLMs), play a crucial role in GIR. These models are trained on massive datasets of text and code, enabling them to understand context, relationships, and nuances in the information. This understanding allows them to generate coherent and informative responses that address the user’s query, rather than just pointing to related documents. For instance, a user asking about the future of electric vehicles could receive a summary of projected advancements, challenges, and market trends, not just a list of articles mentioning electric vehicles.
Comparison with Other Retrieval Methods
Traditional information retrieval methods, like vector space models and probabilistic models, primarily focus on retrieving documents containing relevant s. In contrast, GIR leverages generative models to synthesize novel content, moving beyond the limitations of matching. This approach offers a more comprehensive and nuanced understanding of the query topic. While retrieval methods like matching are efficient for simple queries, GIR excels at complex and multifaceted inquiries.
Other methods like collaborative filtering and semantic search can improve accuracy, but GIR often surpasses them in the ability to generate novel insights.
Potential Impact on Information Access
GIR has the potential to revolutionize information access by providing more comprehensive and contextually relevant answers. Instead of just pointing to related documents, GIR can synthesize information and provide insights that traditional methods cannot. This approach can make complex topics more accessible to a wider audience.
Examples of Improved Retrieval Accuracy
Generative models can be used to improve retrieval accuracy in various ways. For instance, a user inquiring about the history of the internet can receive a detailed narrative encompassing key events, technological advancements, and societal impacts, rather than just a list of articles. Furthermore, GIR can summarize complex scientific papers or condense vast amounts of data into concise, meaningful responses.
Benefits for Users
GIR offers several benefits to users. It provides more comprehensive and nuanced answers to complex queries. The generated responses often provide insights beyond the scope of existing documents, enhancing user understanding and knowledge acquisition. GIR can be tailored to individual user preferences and needs, leading to a more personalized and effective information retrieval experience. This is particularly beneficial for complex queries that require synthesizing information from various sources.
Generative Models in Search
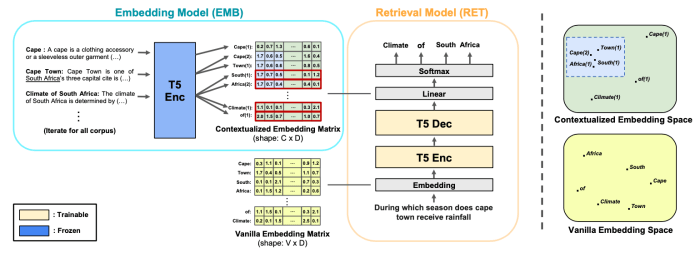
Generative models are revolutionizing information retrieval, moving beyond matching to generate human-like text summaries and snippets. This shift allows search engines to provide more comprehensive and contextually relevant results, enhancing user experience and efficiency. Instead of just pointing users to documents, generative models can actively create summaries and answers directly within the search results.This approach addresses limitations of traditional -based search, where results might not capture the full meaning or context of the user’s query.
Generative models are poised to improve the quality and relevance of search results, creating a more intuitive and informative user experience.
Types of Generative Models Suitable for Information Retrieval
Generative models, like large language models (LLMs), are well-suited for information retrieval. These models are trained on massive datasets of text and code, enabling them to understand and generate human-like text. Variational autoencoders (VAEs) and Generative Adversarial Networks (GANs) are also applicable, though LLMs are currently more prevalent in retrieval tasks due to their strong performance. The choice of model depends on the specific retrieval task and the desired output format.
Generating Relevant Information Snippets
Generative models generate relevant snippets by understanding the context of the query and the underlying documents. They predict the most likely continuation of the text, creating coherent and relevant summaries. This is achieved by analyzing the statistical relationships between words and phrases within the training data. For example, if a user searches for “best coffee shops in Seattle,” the model might predict the following snippet: “The best coffee shops in Seattle are known for their unique brews and vibrant atmospheres.
Pike Place Coffee is a must-try, with its iconic location and renowned espresso.”
Examples of Models Used for Text Generation in Retrieval Contexts
Several pre-trained language models excel at text generation for retrieval tasks. BERT (Bidirectional Encoder Representations from Transformers), GPT-3 (Generative Pre-trained Transformer 3), and LaMDA (Language Model for Dialogue Applications) are prominent examples. These models are capable of generating diverse text formats, including summaries, answers, and explanations, based on input queries and relevant documents.
Utilizing Pre-trained Language Models
Pre-trained language models are readily available and can be fine-tuned for specific retrieval tasks. Fine-tuning involves adjusting the model’s parameters to better match the specific characteristics of the dataset being used. This process allows for improved accuracy and relevance in generating results for a particular domain or type of query. This can be done by providing examples of queries and desired responses to the model during the fine-tuning phase.
Basic Architecture for Integrating Generative Models into a Search Engine
A basic architecture for integrating generative models into a search engine involves these key components:
- Query Processing: The system first processes the user’s query to extract relevant s and understand the intent.
- Document Retrieval: Based on the processed query, relevant documents are retrieved from the document store.
- Generative Model Inference: The generative model then takes the retrieved documents and the query as input to generate a concise and relevant summary or answer.
- Output Generation: The generated output, including the summary or answer, is formatted and presented to the user in the search results.
Components of a Generative Information Retrieval System
A complete generative information retrieval system includes several interconnected components:
- Query Understanding Module: This module interprets the user’s query, identifying the intent and s.
- Document Retrieval Module: This component fetches relevant documents from the database.
- Generative Model Module: This core module generates the response, summarizing information from retrieved documents based on the query.
- Ranking and Filtering Module: This module sorts and filters the generated results based on relevance and quality criteria.
- User Interface (UI) Module: This module displays the results in a user-friendly format, often including visual aids.
Performance Comparison of Generative Models
The following table provides a comparative analysis of the performance of various generative models in information retrieval tasks. Factors like accuracy, efficiency, and ability to handle diverse queries are considered.
| Model | Accuracy | Efficiency | Diversity Handling |
|---|---|---|---|
| BERT | High | Moderate | Good |
| GPT-3 | Very High | High | Excellent |
| LaMDA | High | High | Excellent |
Retrieval Strategies
Generative information retrieval methods are not simply about finding documents; they’re about constructing a response tailored to the user’s query. This necessitates sophisticated retrieval strategies that go beyond traditional matching. These strategies need to understand the nuances of the query, the context of the information, and the user’s likely intent. This allows the system to produce more relevant and insightful results.Different generative models employ various retrieval strategies, leveraging their unique strengths to enhance search accuracy and user experience.
These strategies often involve intricate steps that consider the semantic meaning of queries and the underlying relationships between documents. The effectiveness of these methods depends heavily on the evaluation metrics employed and the quality of the data used to train the models.
Different Retrieval Strategies Employed by Generative Search Methods
Generative search methods employ a range of retrieval strategies beyond simple matching. These strategies often involve a multi-step process, starting with query understanding and progressing to document selection and response generation. Some common strategies include:
- Semantic Search: This approach focuses on understanding the meaning behind user queries, going beyond just matching s. It leverages techniques like word embeddings and natural language processing (NLP) to grasp the semantic relationships between words and concepts. This allows the system to retrieve documents relevant to the underlying meaning of the query, rather than just those containing similar s.
For example, a query like “best restaurants for a romantic dinner” might retrieve results beyond those simply containing the words “restaurant” and “dinner,” focusing on restaurants with a romantic ambiance.
- Knowledge Graph Retrieval: By leveraging knowledge graphs, generative models can connect information from different sources. This allows the system to go beyond individual documents and consider the relationships between concepts, providing a richer and more interconnected understanding of the search topic. Imagine a query about the impact of climate change on agriculture. A knowledge graph approach might not only retrieve documents directly on that topic, but also those connecting climate change to specific crops, or the economic implications for farmers.
- Contextual Retrieval: This strategy considers the context surrounding the query, such as previous interactions with the system or the user’s profile. By understanding the user’s background and interests, the model can personalize the search results, tailoring them to the specific needs of the individual. For example, if a user frequently searches for information about a specific company, the system can anticipate their next query and provide relevant results without them having to re-enter the company name.
Challenges in Evaluating Generative Search Strategies
Evaluating the effectiveness of generative search strategies presents unique challenges. Traditional evaluation metrics, such as precision and recall, are often insufficient for capturing the nuanced quality of the generated responses. Subjectivity plays a significant role in assessing the quality of a generated text, making comparisons and establishing benchmarks difficult.
- Measuring Relevance in Generated Responses: Assessing the relevance of a generated response is complex. Traditional relevance metrics might not adequately capture the richness and depth of information provided by a generative model. This requires developing new metrics that consider factors like fluency, coherence, and factual accuracy in addition to topical relevance.
- Handling Subjectivity and Nuance: Human judgments about the quality of a response often involve subjective assessments. This can make it difficult to develop objective and reliable evaluation metrics that can account for different perspectives and interpretations.
- Creating Large-Scale, Representative Datasets: Developing datasets large enough to evaluate generative search models effectively is challenging. These datasets must capture the diversity of user queries and the range of potential responses, ensuring they are representative of real-world usage.
Strengths and Weaknesses of Various Generative Retrieval Methods
Different generative models have varying strengths and weaknesses in their retrieval capabilities. The choice of model depends heavily on the specific application and the characteristics of the data.
| Model | Strengths | Weaknesses |
|---|---|---|
| Transformer-based models | Excellent at understanding context and generating human-like text | Can be computationally expensive and require large amounts of training data |
| Retrieval Augmented Generation (RAG) | Combines the strengths of retrieval and generation, resulting in high-quality responses | Performance can depend on the quality of the underlying retrieval system |
| Knowledge Graph Embeddings | Leverages structured knowledge to enhance retrieval | Limited by the coverage and accuracy of the knowledge graph |
Dynamic Adaptation to User Queries
Generative models can dynamically adapt to user queries by learning from user interactions and preferences. This allows the system to tailor the search results to the specific needs and interests of the individual user.
Impact of Query Understanding on Retrieval Quality
The accuracy of query understanding significantly impacts the quality of retrieved information. If the system fails to grasp the user’s intent, the results will likely be irrelevant or misleading. Sophisticated query understanding techniques, such as semantic parsing and natural language processing (NLP), are crucial for accurate retrieval.
Factors Influencing the Quality of Retrieved Information
Several factors influence the quality of retrieved information from generative search methods. These include the quality of the training data, the sophistication of the retrieval models, and the effectiveness of the evaluation metrics used.
Optimizing Retrieval Strategies Based on User Feedback
User feedback is crucial for optimizing retrieval strategies. By incorporating feedback into the model training process, the system can learn from its mistakes and improve its performance over time. This iterative refinement allows for dynamic adjustments to the search strategy.
Evaluation Metrics
Generative information retrieval (GIR) introduces a new dimension to search, requiring innovative evaluation metrics beyond the traditional methods. Simply measuring recall and precision, while useful, doesn’t capture the nuances of generated content, such as its novelty, quality, and impact on user experience. This section delves into suitable evaluation metrics for GIR, highlighting limitations of conventional approaches, and proposing a framework for a more comprehensive assessment.
Traditional Evaluation Metrics Limitations
Traditional metrics like precision and recall, while fundamental for evaluating retrieval systems, struggle to capture the specific characteristics of generative outputs. They primarily assess the correctness of retrieved documents rather than the quality or novelty of the generated content. For instance, a system might retrieve highly relevant documents but generate summaries that lack originality or are simply paraphrases of existing information.
These systems would perform well under traditional metrics but fail to deliver the innovative search experience that generative models promise.
Suitable Evaluation Metrics for Generative Information Retrieval
A comprehensive evaluation of GIR systems needs to consider factors beyond simple relevance. Metrics should assess the quality and novelty of the generated content, and its impact on user experience. The following metrics provide a more holistic perspective:
- Novelty Score: This metric assesses the originality and uniqueness of the generated content. It can be calculated by comparing the generated text against a large corpus of existing text, identifying overlapping phrases and concepts. A high novelty score indicates that the generated text contains novel information not easily found elsewhere. For example, a system generating a synthesis of multiple research papers, presenting a unique perspective, would receive a high novelty score.
- Quality Score: Evaluates the grammatical accuracy, coherence, and readability of the generated text. This could involve automated metrics based on linguistic analysis or human evaluation through surveys or expert ratings. A system producing grammatically correct, coherent, and easily understandable summaries would score high on quality. Examples could be the readability score or fluency score.
- User Engagement Metrics: These metrics assess the user’s interaction with the generated information. Examples include time spent on the page, click-through rates, and the number of questions asked. A high level of user engagement suggests the generated content is useful and interesting. Consider user feedback questionnaires.
Metrics and Use Cases
| Metric | Description | Use Case |
|---|---|---|
| Precision | Proportion of retrieved documents that are relevant. | Assessing the accuracy of retrieved information. |
| Recall | Proportion of relevant documents that are retrieved. | Evaluating the completeness of the retrieved information. |
| Novelty Score | Measure of originality of generated content. | Evaluating the creativity and uniqueness of generated responses. |
| Quality Score | Assessment of grammatical accuracy, coherence, and readability. | Evaluating the overall quality and usability of generated content. |
| User Engagement Metrics | Measures user interaction with generated content. | Evaluating the impact on user experience and satisfaction. |
Calculating and Interpreting Metrics
Precision and recall are calculated as the ratio of relevant retrieved items to the total retrieved items and relevant items, respectively. Novelty scores can be determined by comparing the generated text against a large corpus using techniques like cosine similarity. Quality scores often involve a combination of automated and human evaluations, and are usually expressed as percentages or numerical ratings.
User engagement metrics are usually tracked by analytics tools and interpreted by observing trends.
Framework for Measuring User Experience
A framework for measuring the impact of generative search on user experience involves multiple stages. Firstly, users are given tasks to perform using both the traditional and generative search systems. Secondly, their actions are tracked, including time spent on each task, clicks, and the types of queries they submit. Thirdly, user feedback is gathered through surveys and interviews.
This framework can help evaluate how quickly and effectively users achieve their goals and the overall satisfaction level.
Measuring Novelty and Quality of Generated Content
Measuring the novelty of generated content involves comparing it against a large dataset of existing text. Similarity scores (e.g., cosine similarity) and unique analysis are crucial in identifying the originality of generated outputs. Quality is often assessed through a combination of automated metrics (e.g., grammatical correctness) and human evaluations (e.g., coherence, readability).
Comparison of Evaluation Methods
Automated evaluation methods are generally faster than human evaluations, but they may not capture the subtleties of user experience or the nuanced quality of generated content. Human evaluations, on the other hand, provide a more comprehensive understanding of user experience and content quality but can be time-consuming and expensive. A balanced approach combining both automated and human evaluations is usually most effective.
Generative information retrieval search is a fascinating field, promising a future where finding the right information is easier than ever. However, as Google continues to push the boundaries of search technology, the extraordinary risk Sundar Pichai is taking with Google search, as detailed in sundar pichai extraordinary risk google search , raises important questions about the potential for bias and misinformation in these new systems.
Ultimately, the challenge for generative information retrieval search lies in ensuring accuracy and responsible development alongside these significant advancements.
Challenges and Opportunities
Generative information retrieval (GIR) promises a revolutionary approach to searching, offering personalized and contextually relevant results. However, this powerful technology is not without its limitations. Understanding these challenges and exploring the potential opportunities is crucial for navigating the evolving landscape of information access. The core concerns revolve around biases, ethical considerations, misinformation, and the very nature of the technology itself.
We will explore these facets to better grasp the path forward.
Limitations and Challenges of Generative Information Retrieval
GIR faces hurdles in ensuring accuracy, consistency, and reliability. The models can hallucinate information, creating outputs that seem plausible but are entirely fabricated. This “hallucination” problem significantly impacts the quality of retrieved information, potentially leading to flawed conclusions and misinterpretations. Moreover, the training data’s inherent biases can perpetuate and amplify existing societal inequalities, impacting the fairness and impartiality of search results.
Finally, the computational resources required for training and running complex generative models can be substantial, making the technology inaccessible to smaller organizations and individuals.
Potential Biases in Generative Models and Their Impact on Search Results
Generative models learn from the data they are trained on. If this training data reflects existing societal biases (e.g., gender, racial, or socioeconomic), the models will likely perpetuate and even amplify these biases in their outputs. This can lead to unfair or discriminatory search results, impacting individuals or groups based on these biases. For example, a model trained on predominantly male-centric datasets might produce search results that undervalue or ignore the contributions of women in a particular field.
Generative information retrieval search is pretty cool, right? It’s all about getting the most relevant results, but optimizing your website for search engines is also key. Using the best SEO plugins for WordPress, like the ones listed on this great resource best seo plugins for wordpress , can help your site rank higher in search results. Ultimately, this all plays a crucial role in ensuring your generative information retrieval search strategy is as effective as possible.
This bias can lead to skewed perceptions and an incomplete understanding of the subject matter.
Ethical Considerations in Generative Information Retrieval
The ethical implications of GIR are substantial. As the technology becomes more sophisticated, concerns about the responsibility for the information generated by these models arise. Who is accountable when a model produces inaccurate or harmful information? Furthermore, the potential for misuse, such as the creation of deepfakes or the spread of misinformation, is a significant ethical concern.
The need for robust mechanisms to mitigate these risks is paramount.
Potential for Misinformation and Disinformation in Generative Search Results
The ability of generative models to create realistic-sounding text opens the door to the creation and spread of misinformation and disinformation. Malicious actors could use these models to generate convincing but false information, potentially impacting public opinion or causing harm. This is a significant challenge that requires the development of countermeasures and safeguards to detect and prevent the spread of such content.
Effective detection methods and fact-checking tools are crucial.
Future Directions of Generative Information Retrieval
The future of GIR hinges on addressing the challenges and harnessing the opportunities. Researchers are exploring ways to improve the accuracy and reliability of generative models, including techniques for detecting hallucinations and bias mitigation. Further research into ethical frameworks and guidelines for responsible development and deployment is crucial. Developing tools for evaluating the trustworthiness and reliability of search results is also a key area of focus.
Generative information retrieval search is pretty cool, right? It’s like a super-powered search engine that can understand what you really want, not just what you type. But, let’s be honest, sometimes that super power gets sidetracked by mindless scrolling on social media – a major time waster. Wasting time social media can seriously impact your productivity.
Thankfully, these new search methods can help you focus on the things that matter, like actually finding the information you need. So, back to the good stuff – generative information retrieval search!
Real-World Applications and Use Cases
GIR has the potential to transform various sectors. In education, it could provide personalized learning experiences tailored to individual student needs. In healthcare, it could assist in research and diagnosis by synthesizing complex medical data. In customer service, it could generate more efficient and personalized responses to inquiries. Examples like these showcase the broad potential of this technology.
Importance of User Privacy in Generative Information Retrieval
User privacy is a paramount concern in GIR. The models require access to user data to generate personalized results, raising concerns about data security and potential misuse. Implementing robust privacy safeguards and transparency in data usage is essential. These safeguards must ensure that user data is handled responsibly and that individuals have control over their information.
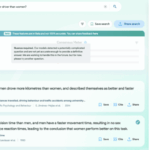
User Interface Design
Designing an intuitive and effective user interface (UI) is crucial for generative information retrieval systems. A well-designed UI can significantly impact user satisfaction and the overall success of the system. Users should be able to easily formulate queries, refine results, and understand the generated information. The UI needs to empower users to actively interact with the system, enabling them to control the retrieval process and gain valuable insights.
User Interface Design Principles
A successful UI for generative information retrieval should prioritize clarity, simplicity, and user control. Users need to be able to easily navigate the system and understand how to interact with different components. The interface should be adaptable, allowing users to customize the presentation of retrieved information to suit their specific needs. The interface should clearly communicate the nature of the generated information, and how users can refine their search.
An intuitive UI design is essential to ensure a positive user experience.
Query Formulation and Refinement, Generative information retrieval search
The UI should support a variety of query types. Users should be able to enter free-form queries, as well as structured queries using s, filters, and other parameters. Interactive components, such as autocomplete suggestions, should be incorporated to aid users in refining their searches and narrowing down the results. A clear visual representation of the query and its parameters will improve user understanding.
This will enhance the accuracy of the search results.
Presenting Generated Information
Effective presentation of the generated information is critical. The UI should display the results in a structured and organized manner. For example, the retrieved information could be presented in a visually appealing format, such as a series of cards or a collapsible tree structure. A clear separation of the generated text from supporting documents, data tables, or images will aid in comprehension.
Visual aids, like charts or graphs, should be used to represent data insights effectively. Clear labeling and formatting will improve user comprehension of the retrieved information.
Interactive Components for Refinement
The UI should offer interactive elements to enable users to refine search results. Features like filtering, sorting, and highlighting specific s within the generated text will allow users to quickly identify relevant information. Users should be able to adjust the length or complexity of the generated responses. Interactive components allow users to exert more control over the search process.
Visual Aids and Interactive Elements
Visual aids, such as charts, graphs, and images, can enhance the presentation of retrieved information. Interactive elements, such as clickable links or expandable sections, can allow users to explore different aspects of the results in greater detail. Clear and concise labeling will ensure users understand the purpose of each visual aid or interactive element.
Incorporating User Feedback
User feedback is essential for iterative UI improvements. Collecting feedback through surveys, usability testing, and direct user input will help identify areas for improvement and refinement. Analyzing user interactions with the system will reveal patterns in how users use the interface and what aspects they find most helpful or problematic.
UI Design Patterns for Generative Search
| Design Pattern | Description | Example |
|---|---|---|
| Card-based Presentation | Information is displayed in a visually appealing card format, with clear headers, summaries, and supporting details. | A news article summary presented in a card with an image, title, and short description. |
| Hierarchical Structure | Information is organized in a hierarchical structure (e.g., tree view) allowing users to explore different levels of detail. | A research paper with sections, subsections, and supporting evidence, presented in a tree-like structure. |
| Interactive Summarization | Users can interactively adjust the length and detail level of summaries. | A summary of a complex scientific report with options to expand or collapse sections. |
Integration with Existing Systems
Integrating generative information retrieval into existing search engines is crucial for leveraging the strengths of both approaches. This integration requires careful planning and execution to ensure a smooth transition and avoid disrupting the user experience. It involves not only technical modifications but also user interface adjustments to make the generative capabilities accessible and intuitive.Existing search engines often rely on complex indexing and retrieval mechanisms.
Generative models, while powerful, require different approaches to knowledge representation and query processing. The challenge lies in seamlessly blending these distinct methodologies to offer users a unified and enhanced search experience.
Methods for Seamless Integration
A key aspect of seamless integration is developing a hybrid approach. This means retaining the strengths of existing systems while introducing the generative component as an augmentative feature. One strategy involves using generative models to enhance existing search results, such as providing summaries, context, or related information. Another strategy involves using generative models for tasks like query expansion or generating new questions to broaden the search scope.
Technical Considerations for Seamless Integration
Several technical considerations need careful attention. Efficient data pipelines are essential to handle the massive amounts of data required by generative models. Robust indexing methods are required to enable rapid retrieval of information from both the traditional index and the generative model’s output. Moreover, efficient query processing mechanisms are needed to ensure that the generative component does not negatively impact the speed and responsiveness of the search engine.
The integration must also consider the potential for biases in the generative model and implement mitigation strategies.
Examples of Augmenting Existing Systems
Generative retrieval can augment existing systems in several ways. For example, a search engine could use generative models to provide more comprehensive summaries of search results, offering users a deeper understanding of the retrieved documents. The system could also use generative models to identify related articles or research papers, thus improving the user’s exploration of a given topic.
Furthermore, generative models could help to automatically categorize and cluster search results, presenting users with a more structured and organized view of the information.
Examples in Different Application Domains
The integration of generative retrieval methods can be applied across various domains. In a medical context, a generative model could synthesize relevant medical information from multiple sources to provide a concise summary of a patient’s condition. In a legal context, a generative model could summarize court cases or legal documents, aiding legal professionals in their research. In the educational domain, a generative model could provide personalized study materials or summaries of complex concepts.
Transitioning from Traditional to Generative Methods
A gradual transition from traditional search methods to generative methods is recommended. This involves starting with a limited integration, such as using generative models to enhance existing search results. Subsequently, the generative component can be progressively expanded to encompass additional features, gradually increasing the reliance on generative models.
Step-by-Step Integration Process
1. Assessment
Analyze the existing search engine’s architecture and data structures. Identify potential integration points and assess the feasibility of the generative model’s integration.
2. Data Preparation
Prepare the necessary data for the generative model. This includes cleaning, preprocessing, and potentially augmenting existing datasets.
3. Model Selection
Select a suitable generative model based on the application requirements and available resources.
4. Integration Design
Design the integration strategy, considering the seamless blending of the generative component with the existing search engine. Prioritize user experience.
5. Implementation
Implement the integration, including data pipelines, indexing mechanisms, and query processing.
6. Testing and Evaluation
Thoroughly test the integrated system to ensure functionality and performance. Evaluate the user experience and the impact on retrieval effectiveness.
7. Deployment
Deploy the integrated system and monitor its performance in real-world use.
Outcome Summary
In conclusion, generative information retrieval search presents a compelling alternative to traditional methods. While challenges remain, the potential for enhanced user experience, improved accuracy, and dynamic adaptation to user queries makes it a promising area of research. The future of information retrieval may very well hinge on the successful development and implementation of these cutting-edge techniques. It’s an exciting time for information seekers and researchers alike.